
【はじめに】
近年、生成AIの業務活用が進む中で、社内文書やナレッジを正確に参照しながら回答を生成するRAG(Retrieval-Augmented Generation)は、企業システムにおける実用的なAI活用手法として重要な役割を担っています。一方で、RAGを導入していても期待したほど精度が上がらず、課題を抱えている企業も少なくありません。
RAGの構築自体は比較的手軽に行えますが、回答精度はシステム構成やデータ設計に大きく影響されるため、専門的知識に基づいた定量評価と分析が不可欠です。
本記事は、すでにRAGを導入している、あるいは導入を検討しているIT部門・DX推進担当者、AIシステムの設計・運用を担う技術者の方を主な対象としています。「RAGの精度をどのように評価し、どのような改善施策が有効なのか」について、当社が開発した「RAG評価分析ソリューション」を用いた具体的な検証結果をもとに解説します。評価指標は、RAGに求められるタスク(質問タイプ)別に設け、改善ステップごとの効果を可視化します。
【RAG評価分析ソリューションとは】
RAG評価分析ソリューションとは、RAGの性能を定量的に測定し、精度が伸びない要因を分析したうえで、改善施策へとつなげるためのソリューションです。RAGの品質向上を、以下の3ステップで支援します。
- 評価
Metaの研究チームが提案したCRAG(※1)で整理された評価観点を参考に、当社が独自に設計した評価方法で性能を測定
※当社の評価は、CRAGの公開データセット/評価実装を使用せず、評価観点に関する公開情報をもとに当社が独自に定義・実装しています。 - 分析
スコア推移と誤答原因を分析 - 改善
検索戦略・データ構成・プロンプトを調整
評価軸は次の8項目です。RAGの性能は「平均点」だけで判断すると、改善の方向性を見誤る場合があります。質問タイプごとの得意・不得意を把握することで、課題に対して最も効果的な改善施策を選びやすくなります。
scroll
| 評価軸 | 意味 | 例 |
| 1.単純質問 | 時間の経過によって変化しない単純な事実を問う質問 | 〇〇さんの誕生日は? |
| 2.比較質問 | 2つのエンティティを比較する質問 | 〇〇さんと△△さん、どちらが先に入社した? |
| 3.条件付き質問 | ある条件下での事実を尋ねる質問 | 2025年1月1日の〇〇社の株価は? |
| 4.集計質問 | 複数の取得結果を集計して答える必要がある質問 | 〇〇さんが取った契約の数は? |
| 5.誤った前提の質問 | 質問に誤った前提・仮定が含まれる質問 | 〇〇さんが先月申請した申請の名前は?(実際には〇〇さんは申請していない) |
| 6.多段階質問 | 複数の情報を連鎖的に組み合わせて答えを導く必要がある質問 | 〇〇さんの部署にいる一番若い課長の名前は? |
| 7.後処理が必要な質問 | 取得した情報に対して推論や計算などの後処理が必要な質問 | 〇〇さんの2025年の有給取得率は? |
| 8.集合質問 | 複数のエンティティの集合を答える質問 | 南半球にある大陸をすべて挙げてください |
【検証内容】
RAG評価分析ソリューションを用いて、どのような改善施策がRAGの性能向上に効果的かを検証しました。
l 評価環境と対象
Dify(生成AIアプリケーション開発基盤)とOllama(ローカルLLM実行環境)を用いて、ローカルで動くLLM+RAGの環境を作成
以下記事にて作成方法を紹介しています。
DifyとOllamaで構築!オリジナルAIチャットボット
- RAGデータ:検証用データ(LLM生成のオリジナル小説「SBC太郎」)
- LLM:Llama-3.1Swallow-8B-Instruct-v0.5
- 評価方法:当社ソリューションでベンチマークを実施し、RAG性能を定量評価。
l 検証の流れ
- 【初期評価結果】:検証を行う上でのベースラインを確認
- 【検証①】 よくある改善手法を例に、定量評価の必要性を確認(テキスト検索 → ハイブリッド検索)
- 【検証②】 精度向上パターン1:単純質問系のタスク対策(チャンク設計・キーワード見直し)
- 【検証③】 精度向上パターン2:誤った前提の質問のタスク対策(プロンプト調整)
- 【検証④】 精度向上パターン3:集合質問系のタスク対策(GraphRAG(※5)導入)
【初期評価結果】
Difyのデフォルト設定で構築したRAGの性能は以下のとおりです。ここでいう「スコア」は、各質問タイプにおける回答の正確性を0〜1で数値化したもので、値が高いほど期待される回答ができていることを示します。
| 1.単純質問 | 0.7 |
| 2.比較質問 | 0.8 |
| 3.条件付き質問 | 0.65 |
| 4.集計質問 | 0.4 |
| 5.誤った前提の質問 | 0.5 |
| 6.多段階質問 | 0.7 |
| 7.後処理が必要な質問 | 0.45 |
| 8.集合質問 | 0.15 |

【検証①:テキスト検索 → ハイブリッド検索】
まずは、先ほどの評価結果を分析せずに、一般的に採用されやすい改善手法の一例としてDifyデフォルトのテキスト検索をハイブリッド検索(※2)に変えてみます。この時、チャンク設定(※3)などの他の設定は変更していません。
結果:
| 1.単純質問 | 0.75 |
| 2.比較質問 | 0.6 |
| 3.条件付き質問 | 0.35 |
| 4.集計質問 | 0.3 |
| 5.誤った前提の質問 | 0.55 |
| 6.多段階質問 | 0.4 |
| 7.後処理が必要な質問 | 0.5 |
| 8.集合質問 | 0.1 |

結果として、全体のスコアは低下しました。検索結果を確認すると、クエリと関係が薄い箇所から取得されているケースが見られました。今回の小説データは文脈依存が強いため、検索語だけでは意図した箇所を安定して取得しにくいことが一因と考えられます。
一方で、質問タイプによってはスコアが上昇している項目もありました。局所的な改善だけを見ると「効果が出た」と判断しがちですが、別の質問タイプでは性能が低下している可能性があります。このようなトレードオフを見落とさないためにも、定量的な評価が重要です。
例:
scroll
| 質問分類 | 質問データ | 模範解答 |
| 単純質問 | SBC太郎が売ろうとしている商品は何? | SBCクラウド |
上記質問に対する回答:
scroll
| 検証方法(検索方法) | RAG回答 | 判定 |
| 初期評価(テキスト検索) | SBC太郎が具体的に何を売っているか、文脈からは特定できません。彼は顧客の困りごとを解決するために働いているようですが、その商品が何かは書かれていません。 | × |
| 検証①(ハイブリッド検索) | SBC太郎が売ろうとしているのはSBCクラウドという商品です。 | ◎ |
【検証②:チャンク設計・キーワード最適化】
では、基礎的な要素から調整します。小説のように文脈が重要なデータでは、文脈を損なわずに必要箇所を引用できるようにすることが重要です。
検証①で導入したハイブリッド検索は一旦やめ、影響範囲を絞って検証するため、逆インデックス(※4)による検索に戻したうえで、チャンク設計とキーワードの見直しを行いました。今回は文脈が途切れにくいよう、元テキストにチャンク識別子を付与し、それに基づいてチャンキングする設計としました。これにより、物語の途中で文脈が分断されることを防ぎ、検索時に意味のまとまりを保ったままLLMへ渡せるようになります。
また、Difyの機能で自動生成されるキーワードは過不足が生じる場合があるため、キーワードの拡充も実施しました。
結果:
| 1.単純質問 | 0.95 |
| 2.比較質問 | 0.85 |
| 3.条件付き質問 | 0.75 |
| 4.集計質問 | 0.5 |
| 5.誤った前提の質問 | 0.5 |
| 6.多段階質問 | 0.65 |
| 7.後処理が必要な質問 | 0.5 |
| 8.集合質問 | 0.3 |

初期評価と比較して、全体の精度を維持しつつ、特定の質問タイプで回答精度が向上しました。特に、画像や表を含まないシンプルなRAG構成であるため、単純質問については高い精度が得られています。
【検証③:誤った前提の質問への対応(プロンプト調整)】
続いて、スコアが低く、かつ改善が見込まれる「誤った前提の質問」への対策を行います。このタイプは、ユーザーの質問自体に誤った前提が含まれるため、RAGとしては誤った前提に引きずられず、「該当する情報がありません」等と適切に回答できれば正解となります。
通常のLLMではハルシネーションにつながりやすい一方で、RAGは検索結果に基づいて回答するため、プロンプト設計により比較的対処しやすい領域です。検索結果から論理的に導けない場合は「情報がありません」と回答するよう、RAGのプロンプトにルールを組み込みました。
結果:
| 1.単純質問 | 0.95 |
| 2.比較質問 | 0.85 |
| 3.条件付き質問 | 0.75 |
| 4.集計質問 | 0.5 |
| 5.誤った前提の質問 | 1 |
| 6.多段階質問 | 0.6 |
| 7.後処理が必要な質問 | 0.4 |
| 8.集合質問 | 0.15 |

結果として、「誤った前提の質問」はすべて正答となりました。なお、他タスクの一部でスコアがわずかに低下していますが、これは、従来は不確かな回答で「部分点」となっていたケースが、ルール適用により抑制された影響と考えられます。
【検証④:集合質問に対するGraphRAG活用】
最後に、標準的なRAG構成の調整だけでは対応が難しいケースとして、最もスコアの低かった「集合質問」の改善を試みます。これは、「物語に登場するSBC太郎の友人をすべて列挙して」のように、文章全体から条件に合致する要素を網羅的に抽出・列挙するタスクです。
一般的なRAGの検索処理では、ヒットした一部の箇所を抜粋してLLMへ渡すため、このような全体を俯瞰して列挙する必要がある問いに弱い傾向があります。
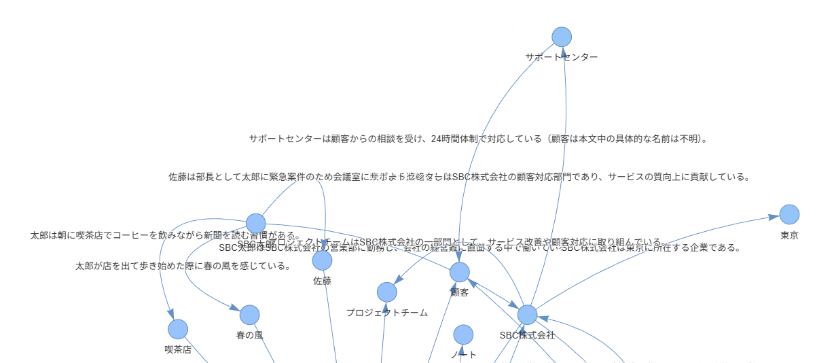
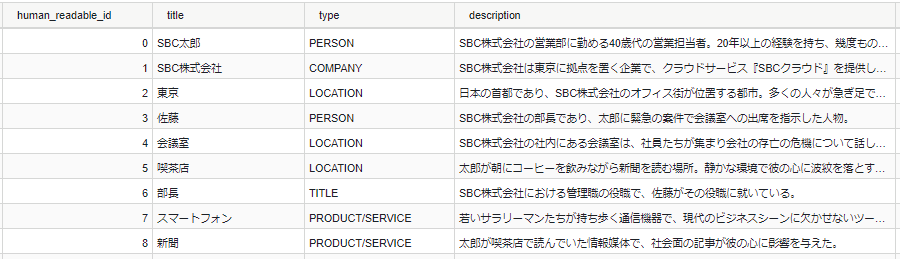
そこで今回は、GraphRAGを用いて対応します。GraphRAGでは事前にテキストをLLMで解析し、人物・場所・関係性などを抽出してナレッジグラフとして整理します。これにより、条件に合致する要素を横断的に参照しやすくなり、集合質問への回答精度向上が期待できます。
本検証では、Difyの質問分類器で質問タイプを判定し、集合質問の場合はGraphRAG側で検索するよう処理を分岐しました。なお、DifyにはGraphRAG機能が標準搭載されていないため、別途GraphRAG環境を構築し、Web APIとしてDifyから呼び出す形で連携しています。
GraphRAGのナレッジグラフイメージ:
GraphRAGのDB:
Difyのチャットフロー:

結果:
| 1.単純質問 | 0.95 |
| 2.比較質問 | 0.85 |
| 3.条件付き質問 | 0.7 |
| 4.集計質問 | 0.7 |
| 5.誤った前提の質問 | 1 |
| 6.多段階質問 | 0.65 |
| 7.後処理が必要な質問 | 0.4 |
| 8.集合質問 | 0.7 |

今回構築したGraphRAGは最小限の調整であるため、一部回答できないケースもありますが、難易度の高いタスクについても、質問タイプに応じて処理を切り替えることで精度向上が見込めることが確認できました。
【さいごに】
RAG評価分析ソリューションは、「定量評価 → 分析 → 改善」というサイクルを繰り返すことで、RAGシステムの性能を着実に向上させます。本記事で紹介したように精度向上の個別テクニックだけでなく、評価指標の設計や分析プロセスの可視化が実運用における品質改善の鍵となります。
当社では今後もより多様なデータやタスクへの対応、最新技術を取り込みながら、RAGの導入や改善において最適なソリューションを提供してまいります。RAGの導入や運用でお困りの際は、ぜひ当社までご相談ください。
先進技術研究開発部
島尾 明宏
※1:CRAG(Comprehensive RAG Benchmark) は、Metaの研究チームが公開した、RAG性能を総合評価するためのベンチマークです。
https://arxiv.org/abs/2406.04744
※2:ハイブリッド検索:「キーワード検索」と「ベクトル検索」を合わせた検索方法で、それぞれの長所を組み合わせることで精度が安定しやすくなると言われています。
※3:チャンク設定:長い文章を「意味のまとまりごと」に小さく分けて保存・検索し、質問に関係する部分だけをAIが正確に見つけられるようにするための設定です。
※4:逆インデックス:「どの言葉が、どの文章に含まれているか」をあらかじめ一覧表のように整理しておくことで、質問に含まれる言葉に関係する文章をすばやく探せる仕組みです。
※5:GraphRAG: Microsoft Research により提唱・整理されているRAG拡張手法の一つで、文章同士の「人・物・関係性」を図(グラフ)のようにつないで整理することで、複数の情報をまたいだ質問にも、文脈を理解して正しく答えられるようにする仕組みです。
https://microsoft.github.io/graphrag/
※Difyは米国LangGenius社の登録商標です。
※OllamaはOllama Inc.の商標または商標登録出願中の商標です。
※GraphRAGはMicrosoft Researchが公開しているプロジェクト/手法の名称です。
※本ページに記載されている製品名、サービス名、会社名などは、それぞれの企業の登録商標または商標です。
※本ページで紹介している構成やツール、パラメータは、検証目的で選定した一例であり、特定の製品や構成を推奨するものではありません。
【公式X(旧Twitter)】